


Hello eCRUSADers! We’re delighted to share a guest blog post by University of Stirling MSc Big Data student, Janine Aitkin, which discusses the RELEASE project — a collaborative study examining access to mental health and substance use services among people released from prison in Scotland, using linked Scottish administrative data. Central to this project is meaningful collaboration with individuals who have lived experience of imprisonment, ensuring that their perspectives inform the design, interpretation, and relevance of the research. The blog offers an insightful overview of this partnership-driven approach and its contribution to enhancing research using large, routinely collected datasets. You can find out more about the RELEASE project in the published study protocol paper here.
By Janine Aitkin, MSc Big Data student, University of Stirling
What is Big Data and Why Does it Matter?
Big Data is often defined in terms of its sheer volume, the speed which it is generated and its function as a powerful analytical tool. Yet, it remains a contested concept, with meaning varying across disciplines and contexts. In the Big Data paradigm, analysis is often focused on identifying patterns and correlations, as opposed to the causes of social phenomena, and prediction is usually favoured over explanation. In some areas, Big Data heavily influences the way we think from understanding why something happens to predicting what is likely to happen, subsequently underpinning a growing culture of prediction and optimisation, with examples stretching from predictive policing to online shopping. Big Data has contributed to the increasing use of automated data analysis techniques, such as machine learning, complementing more traditional approaches like hypothesis driven statistical methods.
Big Data not only refers to volume, it also refers to datafication (the process of turning much of life into data). This transformation often occurs passively, through the collection of information by mobile phone apps, sensors, CCTV and other digital technologies, often without users’ active participation. This passive data collection contributes to what scholars have termed ‘double data’, whereby data are generated about the world (movement, behaviour, location) and about the actual data (usage patterns, device information, timestamps, metadata). The second layer of data provides context, enabling deeper analysis and insights that delve deeper into the data’s meaning. This is achieved by providing a representation of how, when and where people are doing things that generate data, thus creating a multi-dimensional digital footprint that can be analysed, monetised and surveilled.
Big Data has been used to shape and advance a wide range of industries and innovations, including medicine, technology, healthcare and government; it has transformed the way we understand the world, influencing how we process data and conduct research. Big data is helpful in facilitating a shift from population samples to the analysis of complete populations (n = all). It allows researchers to explore specific subgroups, with greater nuance, such as men from minority ethnic groups under the age of 30. However, the ‘n = all’ claim is more aspirational than factual. In practice, big data sets, particularly those derived from social media or administrative records, often contain gaps, exclusions or biases due to how data are generated. This might include those without digital access or those who choose not to participate, resulting in underrepresentation. Even in studies that appear to include entire populations, such as linking specific cohorts (such as all people released from prison) to health records, some individuals may not be identifiable in health records, thus making ‘n = all’ an approximation rather than a reality. Quantitative social sciences have long focused on subgroups, therefore what Big Data offers is not a new capability but a different kind of access, by providing larger sample sizes that would be challenging using traditional methods.
Big Data in Criminal Justice: Promise or Peril?
A growing body of research highlights the profound impact of Big Data on the criminal justice system, particularly through the integration of artificial intelligence to analyse large quantities of data, with the aim of minimising human subjectivity. Whilst these technologies promise greater efficiency and predictive capability, they have sparked debate around protecting human rights, potential bias, privacy and data security.
Common Critiques and Ethical Challenges
Although Big Data is often claimed to be objective and accurate, research increasingly shows that such claims can be misleading (see Barocas and Selbst, 2016). Data analysis is not a neutral process, it involves human decision making, assumptions, interpretation, and potential bias at every stage. Moreover, larger data sets are not inherently better; they often contain noise, irrelevant variables and systemic bias – all of which require rigorous methodological and ethical consideration. This includes:
- Data cleaning and preprocessing to reduce or remove noise and irrelevant variables.
- Auditing datasets to identify systemic bias and ensure representativeness.
- Using fairness aware algorithms that correct imbalances in standard algorithms, thus promoting ethical and socially responsible artificial intelligence (AI).
- Ensuring validity (are you measuring what you intend to measure) and reproducibility (can others replicate using the same methods), which is achieved by reporting on methods, standardisation of tools and protocols, peer review and open data practices.
- Finally, adhering to ethical practices such as respecting privacy, consent and data protection.
Importantly, working solely with large data sets also risks stripping away context and nuance, particularly when used without input from those affected by systems being analysed. The involvement of people with relevant, real-world experiences are essential for providing nuance and context to data, minimising bias during interpretation and bringing perspectives and knowledge that the researchers lack. This is important when working on projects about groups whose voices are often marginalised, and for whom data collection is very contentious. One approach to involvement is demonstrated in the RELEASE project, which is a retrospective cohort study using linked administrative data to examine mental health and substance use related healthcare contacts following imprisonment.
RELEASE: An example of involving people with Lived Experience in big data research
RELEASE demonstrates how Big Data can be analysed more meaningfully by involving people with lived experience to investigate how people access health services for mental health and substance use, following release from prison. RELEASE has a co-investigator with experience of imprisonment, who has been involved from the point of writing the application. This co-investigator convened a Lived Experience Advisory Panel (LEAP) throughout, consisting of individuals with experience of the Scottish prison system. The LEAP provided input on the research and helped focus, interpret, and contextualise findings. Their input has added vital context to understand the data and ensured that the research was grounded in the lived realities of the people most affected by imprisonment. We created the RELEASE dataset by linking routinely collected Scottish administrative prison and health data, including national datasets from Public Health Scotland (PHS) and National Records of Scotland (NRS): General Acute Inpatient and Day Case (SMR01); Mental Health Inpatient and Day Case (SMR04); Unscheduled Care Datamart (UCD); Prescribing Information System (PIS); Outpatient Appointments and Attendances (SMR00); Scottish Drug Misuse Database (SDMD); National Drug Related Deaths Database (NDRDD); National Records of Scotland Deaths Data (NRSDD). We also received demographic information from PHS, and the Prisoner Records 2 datasets from the Scottish Prison Service, which is a prisoner record management system covering admissions, liberations and demographics . In total, and with the support of the Electronic Data Research and Innovation Service (eDRIS), we created a cohort of everyone released from prison in 2015 (n = 8,3,13), and a general population sample (n = 41,213) matched on sex, age, postcode and the Scottish Index of Multiple Deprivation, and with no previous prison experience. In addition to receiving ethical approval from the University of Stirling’s General University Ethics Panel, we also received approval (from the Public Benefit and Privacy Panel for Health and Social Care (HSC-PBPP; application number: 2021-0145). To read more about the RELEASE dataset and linkage process, our protocol is due to be published in the International Journal of Population Data Science in October 2025.The study findings are striking, highlighting high disparities in service contact. Figure 1 below demonstrates that a higher proportion of people released from prison had at least one contact with all services included in the study. Contact with community prescription and outpatient services were experienced by the highest proportion of people in both, but the greatest differences in proportions and rates of contact were seen in services dealing with more acute and urgent needs (like accident and emergency).
Compared to the matched general population sample, people released from prison:
- Visited A&E at a rate six times higher for mental health or substance use.
- Had a rate of ambulance call outs for mental health or substance use that was seven times higher.
- Had general hospital admissions for mental health or substance use eight times more frequently.
- Were more than nine times as likely to die (all causes) in the four years post-release.
A high reliance on emergency services and a stark difference in mortality rate suggests a lack of sustained, preventative, community-based care, particularly for people suffering distress due to poor mental health and substance use needs. These findings underscore the persistent health inequalities faced by people following imprisonment and highlights the urgent need for targeted pre and post-release support and interventions.
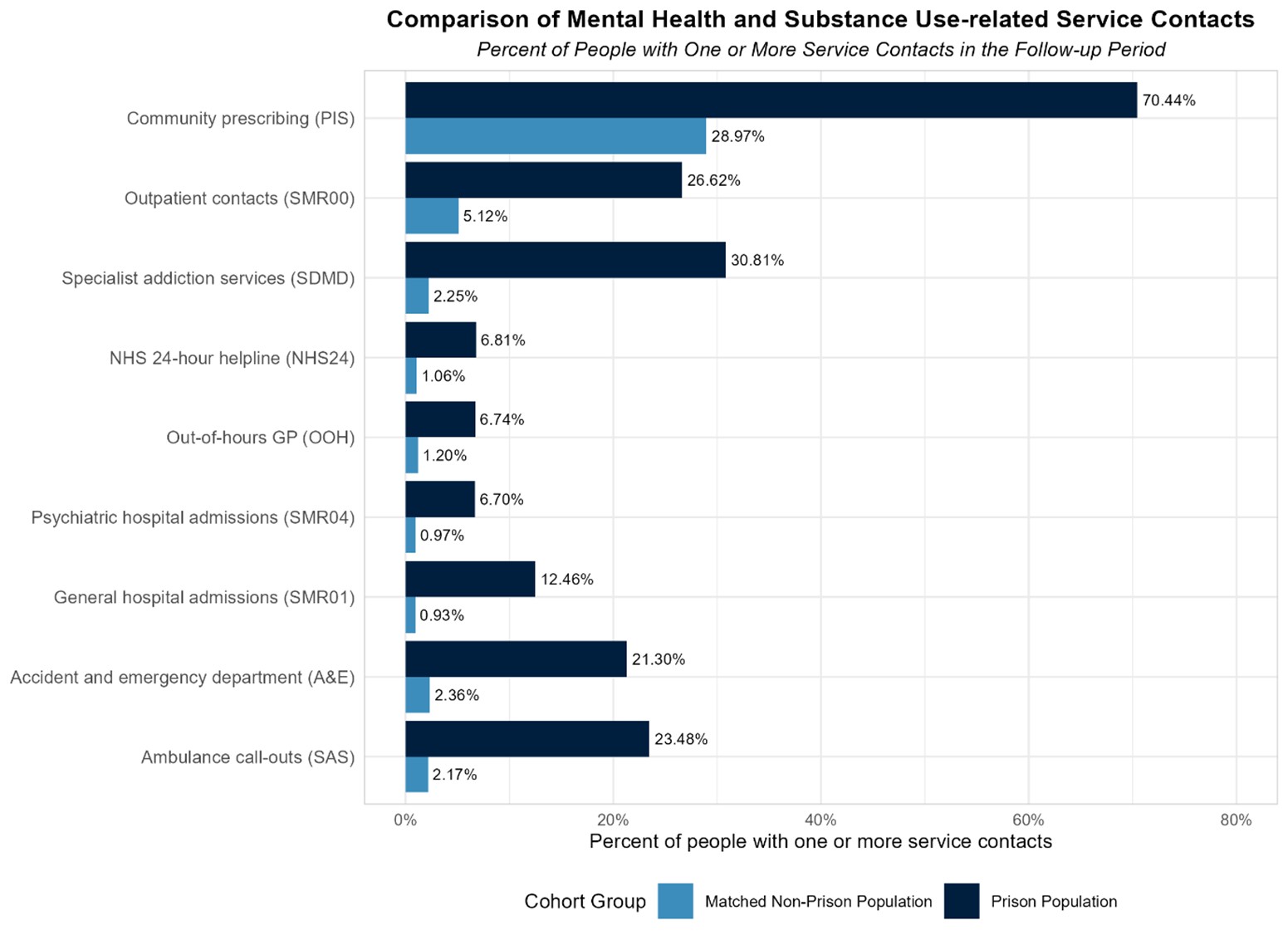
Figure 1: Percent of people with one or more service contacts in the follow up period, by service type and prison exposure group.
Whilst this analysis is incredibly helpful and suggests that people released from prison do not access services early enough, it does not provide any information on the reasons why this is the case, therefore the input of LEAP has provided deeper insights. During the final LEAP, members described a range of potential reasons for the results we observed. They highlighted times that people cannot access services in some areas due to the threat of violence. They also highlighted that people who have served a sentence (especially when lengthy) are being released into the community and expected to be able to use advanced newer technologies to access services online. This places them at a serious disadvantage. Most spoke about the stigma they experienced from services due to their experience of substance use, mental health, and custodial sentences. Finally, individuals shared that post-release licences can be restrictive, acting as a barrier to rebuilding a ‘normal’ life and accessing services. For example, Supervised Release Orders can apply for up to 12 months and often set conditions to remain at a certain address; avoid particular areas, people and places; or attend programmes. The LEAP suggested where focus on in more nuanced analysis to see if some people had better/worse outcomes, and were interested in sexual and gender identity. The RELEASE team are taking forward these suggestions and planning qualitative work to explore the insights shared by the LEAP.
Concluding reflections: Why Lived Experience Matters
The RELEASE results confirm the need for large-scale data analysis that incorporates lived experience perspectives. By involving people with lived experience, the team enhanced the study’s relevance, strengthened its ethical foundation, and gained deepener insights into their systemic issues.
More generally, incorporating lived experience into designing research questions and data analysis can significantly improve the quality and relevance of insights derived from research utilising Big Data and Big Data methodologies. Lived experience can provide a much deeper understanding of the context behind the data, thus helping with interpretation. Engaging diverse voices ensures that data analysis is more inclusive and equitable, with potential to reduce bias in interpretation.
Including people with lived experience provides insights that can inform future qualitative and quantitative research, in turn fostering trust and credibility in a research team. By ensuring that the people who have been impacted by imprisonment (or other experiences of marginalisation) have a voice, are heard and respected, shows that their experience is valued and that these values are in line with ethical research practices.
Big Data has undoubtedly transformed the landscape of research, policy and practice across diverse fields, including criminal justice. While its analytical power offers unprecedented opportunities for understanding and addressing complex issues, it also raises critical ethical, social and methodological challenges. The RELEASE project illustrates the value of combining large-scale data analysis with the voices of the people most affected, highlighting the need for involvement to ensure research is relevant and responsible. Ultimately, integrating lived experience into Big Data research not only enriches our understanding but also supports the development of more effective, just and equitable solutions.